#카프카란
메세징 모델의 일종으로 분산환경에 특화되어 설계되어 있다.
특히 실시간 데이터 분석,처리할 때 데이터 양이 많다보니 대용량 분산 메시징으로 카프카가 많이 언급된다
메시징 모델은 크게 큐 모델과 publish-subscribe 모델로 나뉘는데 카프카는 publish-subscribe 모델에 해당된다.
- 큐 모델: 메시지가 쌓여있는 큐로부터 메시지를 가져와서 consumer pool에 있는 consumer 중 하나에 메시지를 할당하는 방식
- publish-subscribe 모델: topic을 구독하는 모든 consumer에게 메시지를 브로드캐스팅하는 방식
기존 메시지 큐와는 달리, 다수의 메시지를 batch형태로 broker(kafka server)에게 한 번에 전달할 수 있어 tcp/ip round trip 시간을 줄일 수 있다.
#카프카 구조
크게 Producer, consumer, broker로 구성된다.
producer는 broker에 메시지를 push하고, consumer는 broker로부터 직접 메시지를 가지고 가는 pull 방식이다

- producer : 메세지 생산(발행)자.
- consumer : 메세지 소비자
- consumer group : consumer 들끼리 메세지를 나눠서 가져간다.offset 을 공유하여 중복으로 가져가지 않는다.
- broker : 카프카 서버
- zookeeper : 카프카 서버 (+클러스터) 상태를 관리 및 연산 처리
- cluster : 브로커들의 묶음
#어떻게 읽고 쓸까

메세지는 topic으로 분류되고, topic은 여러개의 파티션으로 나눠 질 수 있다. 파티션내의 한 칸은 로그라고 불린다.
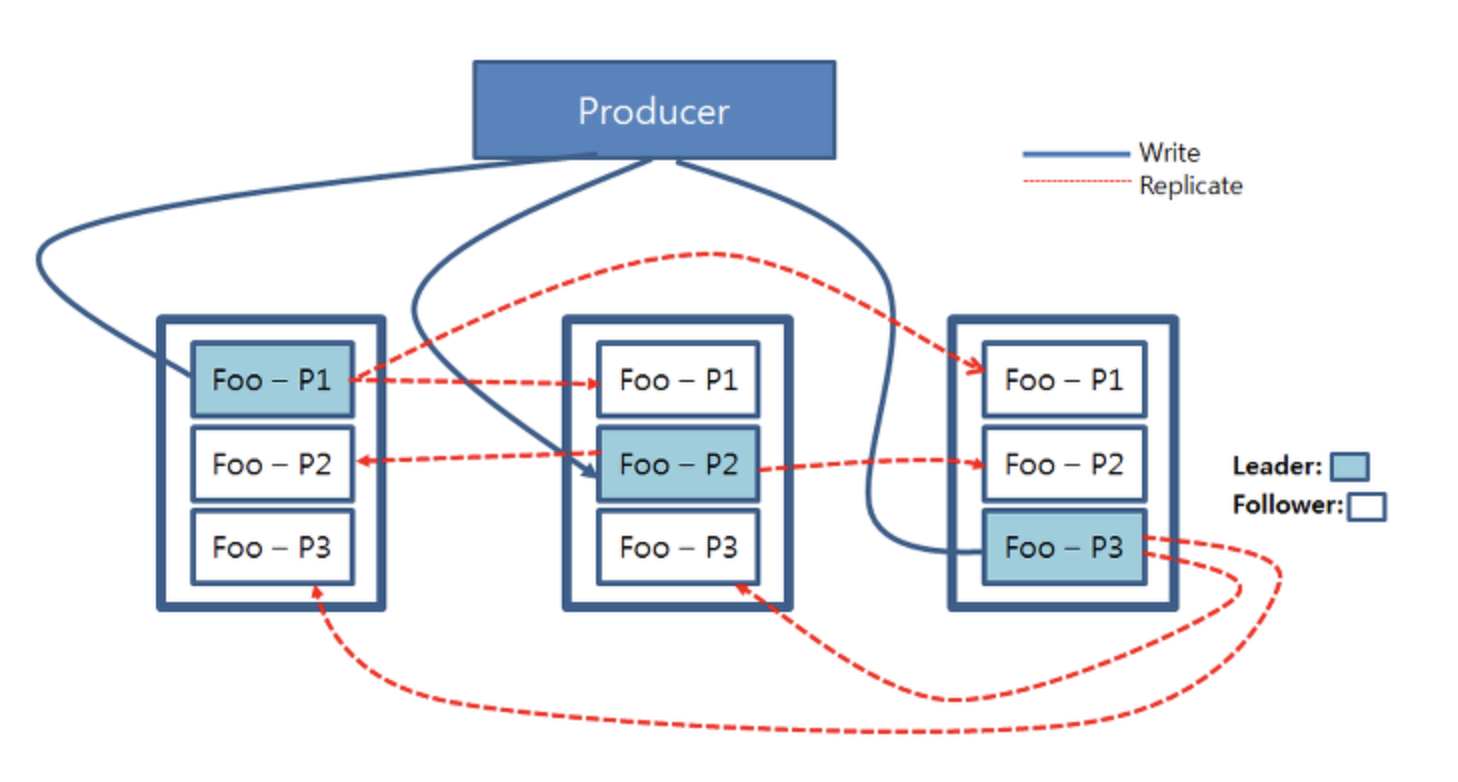
파티션에도 종류가 있는데 leader 파티션 1개와 나머지 follower 파티션들로 구성되어 있다. 카프카에서의 쓰기, 읽기 연산은 카프카 클러스터 내의 리더 파티션들에게만 적용된다. 하늘색으로 칠해진 각 파티션들은 리더 파티션이며 이 파티션들에게 프로듀서가 쓰기 연산을 진행한다. 그리고 리더 파티션에 쓰기가 진행되고 난 후 업데이트된 데이터는 각 파티션들의 복제본들에게로 복사된다.

쓰기 연산을 진행할 때 카프카는 데이터를 순차적으로 디스크에 저장한다. 이 때 파티션들은 각각의 데이터들의 순차적인 집합인 offset으로 구성되어 있다

읽기 연산에서 컨슈머그룹의 각 컨슈머들은 파티션의 offset을 기준으로 데이터를 순차적으로 처리하게 된다 그리고 그룹 내에 있는 컨슈머들은 서로 다른 파티션 데이터를 처리해야만 한다.(즉 1:1 의 느낌이다)
#언제쓸까
메세지 큐의 목적은 단순하다. 메세지를 한 곳에 던지고 그걸 필요한 주체가 가져다 처리한다. 특히 메세지큐를 가장 많이 쓰는 서비스는 로그 관리라고 생각된다. 어느 서비스든 로그관리의 필요성을 가지고 있고 그에 맞는 로그 시스템을 구축한다.
#왜 카프카인가?
1.파일 시스템을 활용한 고성능 설계
기존 메시지 큐와는 달리 메시지를 메모리대신 파일 시스템에 쌓아두고 관리한다
디스크가 메모리보다 느린게 일반적이지만 특정 조건에선 더 빠르기도 하다
하드디스크의 순차적 읽기 성능은 메모리의 랜덤 읽기 성능보다 뛰어나다
즉 Kafka의 메시지는 하드디스크로부터 순차적으로 읽혀지기 때문에 훨씬 빠르다.
2.기존 queue 들과 성능 비교
- Producer 성능

- Consumer 성능

물론 빠르다는 이유로만 쓴다면 다른 메세지 큐들은 도태되서 사라졌을 것이다.
하지만 각각 장단점이 있기에 상황에 따라 쓰이게 된다.
많은 메세지 큐가 있지만 대표적인 RabbitMQ와 비교해보았을 때,
분산과 고성능을 추구하면 당연 카프카가 맞고 굳이 분산까지 해가며 트래픽을 감당할 규모가 아니라면 RabbitMQ를 쓰는 것이 좋다.
댓글